
When you’re working out your procurement strategy you need the right level of data granularity. But often the data in your corporate systems is not structured in a way that is most useful for buyers. Enter Spend Classification: the process of taking raw or partially structured spend data and mapping it to a category hierarchy.
Historically, this been done by a combination of rules and oversight from a human analyst. Developing these kinds of rules is very time-consuming and prone to error.
For example, think of the mobile problem. The following four descriptions all use the word ‘mobile’ in them but relate to vastly distinct types of purchase.
- Mobile application
- Mobile phone
- Mobile billboard
- Mobile office
To handle this case, you would have to write at least 4 rules. I say ‘at least’ because you also must take account of data drift. Different people in various places write descriptions slightly differently. For example, ‘billboard’ could be abbreviated in all kinds of ways which would need more rules to handle.
You could easily end up with millions of rules. No human could keep on top of this.
Benefits of Using Transformers
Fortunately, recent advances in machine learning mean that we can have the machine figure out for itself what these rules should be. The machine learning techniques available nowadays – Transformers – can handle tens or hundreds of millions of different parameters, meaning they can correctly categorize data to a much higher level of accuracy than ever before.
Here is a summary of some recent results we are seeing at Simfoni:
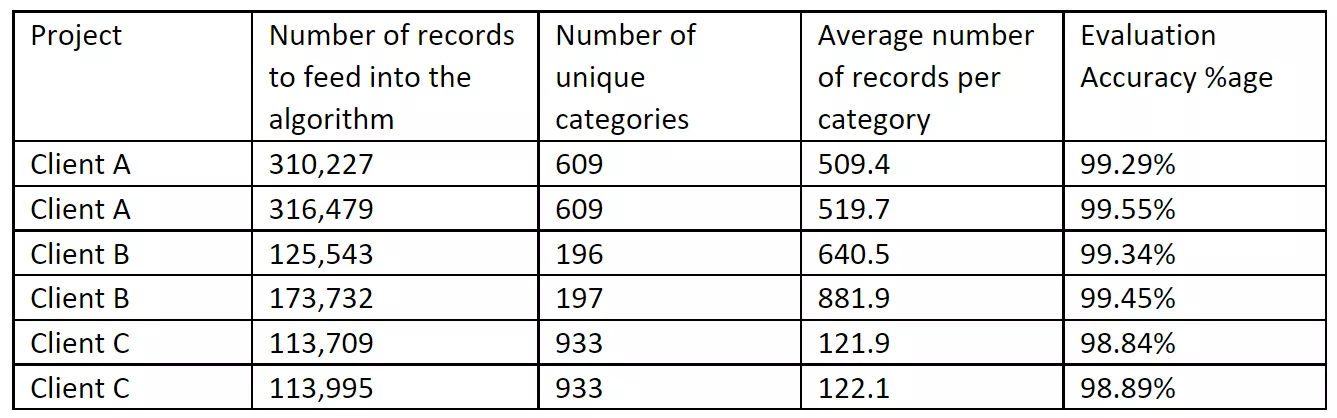
The results are outstanding, and clearly show that as the amount of data increases you can expect to increase accuracy.
In addition to the increase in speed/accuracy of classification, especially for refreshes, we are seeing some other benefits:
- The structure needed for this kind of true machine learning means that we are now able to identify inconsistencies in the source data – where an item has been mapped to more than category – more easily
- Where we can use category hierarchies that are consistent with each other (i.e., they all use different subtrees from one overall hierarchy) we are able to use data learnt from one client to improve the quality of classification for other clients, without impacting any confidentiality concerns.
How Transformers Improve Upon Previous Machine Learning Techniques
Let’s take a trip through the recent history of machine learning, specifically machine learning as applied to natural language processing, to see how recent techniques succeed where previous versions struggled.
It’s worth thinking about natural language processing in spend classification as a two-step process.
- Converting text from your purchasing data into numbers that a computer can understand (also known as tokenization)
- Processing these numbers through a machine learning model to train it on how to select (or ‘infer’) the most likely spend category for each line of spend
Then you can use this model to run inference on new data from every spend refresh, and even use this new data to further train the model to make its categorisation better and better over time.
(Simplified) History of Tokenization
The oldest and simplest version of tokenizing text is to break up a string of text into words and then to assign each word a unique number. Think of this as giving every word in a dictionary its own number, starting at one. This technique is usually called one-hot vectors. It is a simplistic approach because each word is treated independently. There is no way you can tell whether word 12345 and 34567 are synonyms, for example.
The next evolution was to create word embeddings. In this approach, each word is given a range of values (usually about 300) that provide some level of meaning about the word. This allows you to do some math on words to find similar-meaning words. The example often given in the literature is: king – man + woman = queen.
Word embeddings are a significant improvement over One-Hot vectors, but they are still word-based. This presents two types of problems:
- They can’t handle spelling changes, e.g., we have seen the word STRAWBERRY abbreviated to STRWBRY.
- They don’t know how to deal with ‘out of vocabulary’ words that they have never seen before. The usual solution to this is to treat all unseen words the same.
One way of minimizing these problems is to pre-process the data before you feed it to the tokenizer. For example, you can try to standardize word spellings between US and UK English, strip out special accents, try to handle expected spelling errors. But this takes you back down the route of having to manually write code that can easily become overly complex.
Enter Sub-Word Tokenizers.
Sub-Word Tokenizers break up words into their constituent parts without needing any specific coding. This approach requires less pre-processing and ensures that you don’t have the same problems with unseen words than with previous techniques. See tokenizer summary for more details on sub-word tokenization.
(Simplified) History of NLP Machine Learning Models
Early machine learning techniques in NLP used a bag of words model. These would look at all tokens independently. This approach does not work well in real life because often the context of a token depends on the other tokens in the sentence.
Neural Networks like Long Short-Term Memory (LSTM) networks addressed this problem by looking at the tokens in the order they appear in the sentence. They start at the beginning of a sentence and moving forwards token by token through the sentence, learning some context from previous tokens as they go through the sentence.

Early machine learning techniques in NLP used a bag of words model. These would look at all tokens independently. This approach does not work well in real life because often the context of a token depends on the other tokens in the sentence.
Neural Networks like Long Short-Term Memory (LSTM) networks addressed this problem by looking at the tokens in the order they appear in the sentence. They start at the beginning of a sentence and moving forwards token by token through the sentence, learning some context from previous tokens as they go through the sentence.
Enter Transformers.
Transformers improve on LSTMs by looking at all the tokens in a sentence at the same time using a technique called Self-Attention. The literature usually uses this example:
- The animal did not cross the road because it was too tired.
- The animal did not cross the road because it was too wide.
In the first example, ‘it’ refers to the animal. In the second, ‘it’ refers to the road. Transformers can handle this kind of challenge better than previous techniques. Illustrated-transformer has a good write-up about how this works.
What this means for Spend Classification
Taken together, these two innovations – self-attention and sub-word tokenization – mean that you can now achieve far higher quality classification with less human intervention than ever before.
Overall, it is now possible to get access to fully categorized spend data at whatever level of granularity your organisation requires, much quicker and more accurately than in the past. With detailed, authentic, and up to date spend data you can make smarter purchasing decisions and better data-driven decisions in support of your organisation’s strategic objectives, whether those be cost savings or risk management, ESG initiatives or anything else.


Alan Buxton
CTO at Simfoni

Simfoni
Follow Simfoni on LinkedIn
